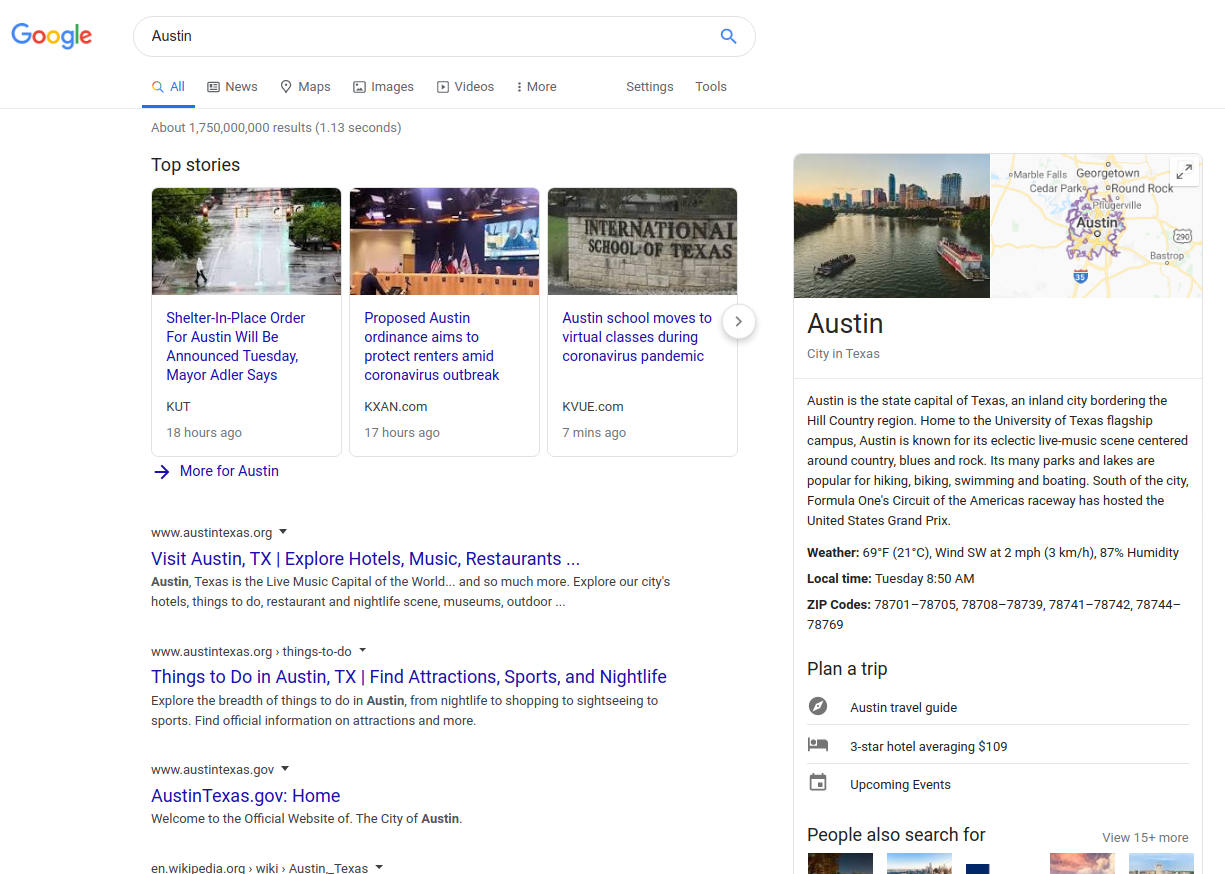



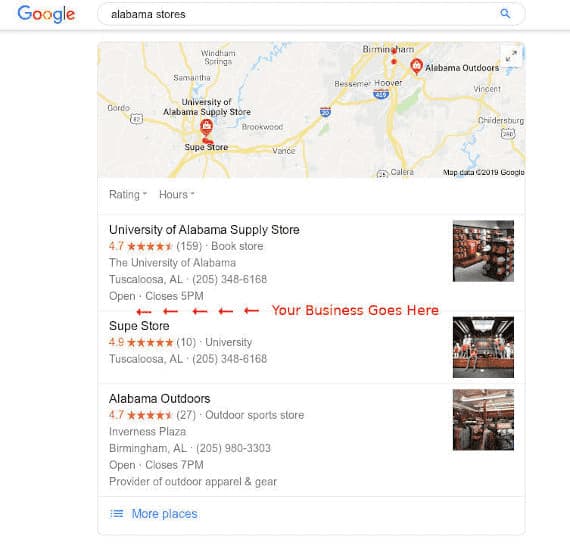
Google Maps
Push your business to the Top 3 Google Maps listings that show up on all devices.
Video SEO
Don't wait for your site to rank. Rank your videos in the YouTube top results and advertise to 1,3 billion users.
FAQ section
How to Block Pages from the Search Results?
You have three options: 1. You could block the page from being crawled in Robots.txt with a 'disallow' command to Googlebot and other bots (User-agent: name-of-bot Disallow: private-URL). It does not mean that all bots will follow the instruction, Googlebot will do though, but most of the others they will ignore it. Since everyone is using Google to search, it will work. Some bots target specifically hidden or private content, so putting the command in Robots.txt gives them a hint of where to find your private pages. The file is also available to anyone typing its path (domain.com/robots.txt) so take note before disclosing private content there.
2. You can insert a noindex tag in the page header. If you don't want to give the bots a hint where to find your content, use the noindex tag only, don't put anything into robots.txt. No guarantees that your content will remain private though, except for Google which is the thing most people care about.
3. If the page is already indexed, you can submit a request to Google to 'temporarily' hide the page from the results (Google Search Console / Removals), and it will work immediately. No worries about the 'temporarily' property, it will remain hidden from Google if you use the robots.txt command or a noindex tag.